MLLM-CL
收藏魔搭社区2026-05-17 更新2025-06-14 收录
下载链接:
https://modelscope.cn/datasets/MLLM-CL/MLLM-CL
下载链接
链接失效反馈官方服务:
资源简介:
---
license: Apache License 2.0
multi_modal:
visual-information-extraction: {}
image-captioning: {}
tags:
- MLLM-CL
- Domain Continual Learning
- Ability Continual Learning
- MR-LoRA
- Continual Learning
- MLLM
---
<!--- 以上YAML section提供属性/tags描述--->
<!--- 以下为markdown格式的dataset描述--->
## MLLM-CL Benchmark Description
MLLM-CL is a novel benchmark encompassing domain and ability continual learning, where the former focuses on independently and identically distributed (IID) evaluation across evolving mainstream domains,
whereas the latter evaluates on non-IID scenarios with emerging model ability.
For more details, please refer to:
**MLLM-CL: Continual Learning for Multimodal Large Language Models** [[paper](https://arxiv.org/abs/2506.05453)], [[code](https://github.com/bjzhb666/MLLM-CL/).
[Hongbo Zhao](https://scholar.google.com/citations?user=Gs22F0UAAAAJ&hl=zh-CN), [Fei Zhu](https://impression2805.github.io/), [Haiyang Guo](https://ghy0501.github.io/guohaiyang0501.github.io/), [Meng Wang](https://moenupa.github.io/), Rundong Wang, [Gaofeng Meng](https://scholar.google.com/citations?hl=zh-CN&user=5hti_r0AAAAJ), [Zhaoxiang Zhang](https://scholar.google.com/citations?hl=zh-CN&user=qxWfV6cAAAAJ)
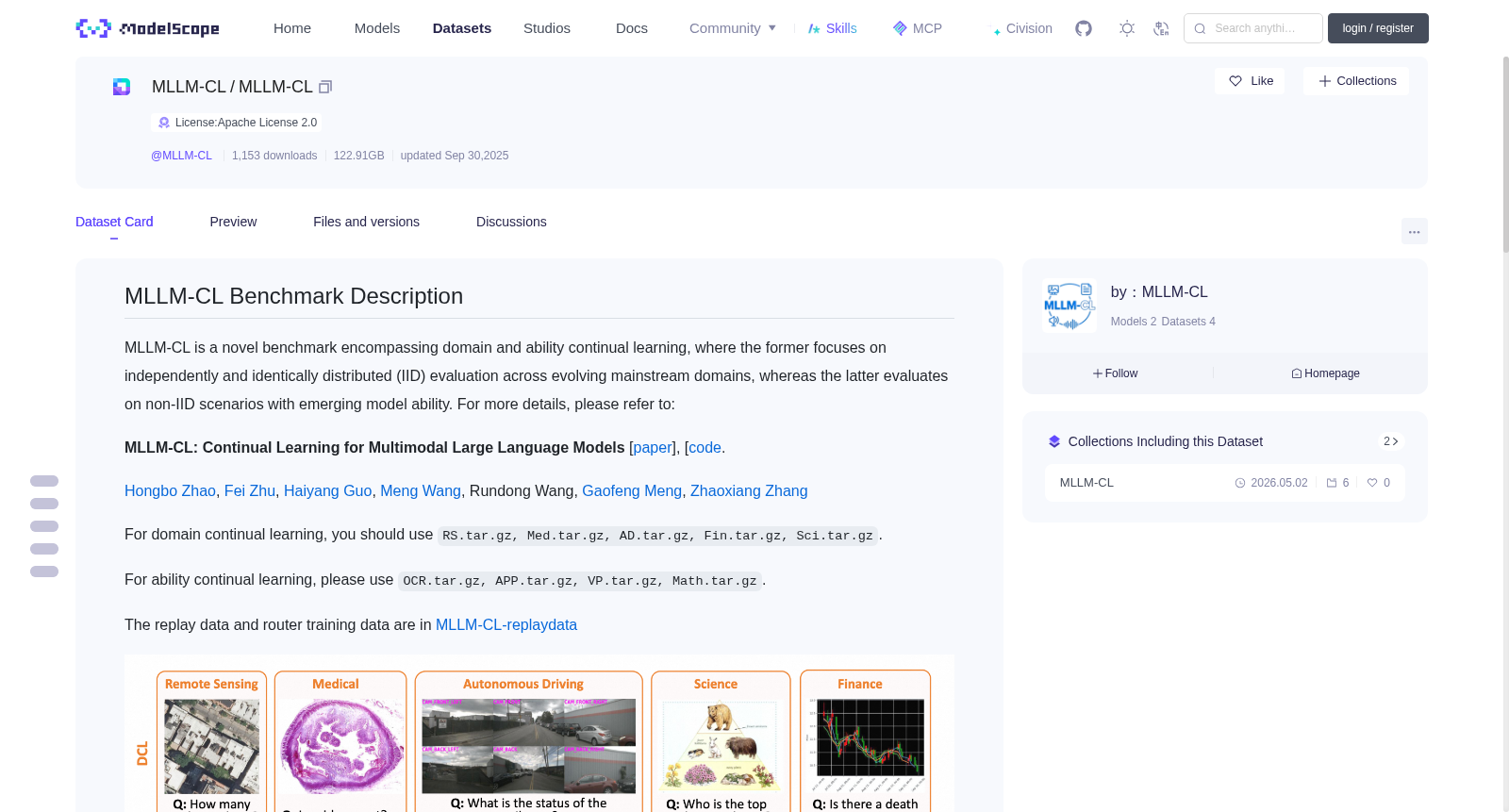
For domain continual learning, you should use `RS.tar.gz, Med.tar.gz, AD.tar.gz, Fin.tar.gz, Sci.tar.gz`.
For ability continual learning, please use `OCR.tar.gz, APP.tar.gz, VP.tar.gz, Math.tar.gz`.
The replay data and router training data are in [MLLM-CL-replaydata](https://modelscope.cn/datasets/MLLM-CL/mllmcl-replaydata)

## Data format
All data is used for SFT stage of MLLM and the json file is in LLaVA SFT format.
```
{
"image": path of image;
"question_id": id;
"conversations": [
{
"from": "human",
"value": "<image>\n"+question or question
},
{
"from": "gpt",
"value": answer
}
]
}
```
## Citation
```
@article{zhao2025mllm,
title={MLLM-CL: Continual Learning for Multimodal Large Language Models},
author={Zhao, Hongbo and Zhu, Fei and Guo, Haiyang and Wang, Meng and Wang, Rundong and Meng, Gaofeng and Zhang, Zhaoxiang},
journal={arXiv preprint arXiv:2506.05453},
year={2025}
}
```
## Contact
Please post an issue in our Github.
## About us: MLLM-CL Community

We are the members from MLLM-CL, an open-source community focus on Continual learning of Multimodal Large Language Models.
If you are interested in our community, feel free to contact us in github or email.
许可证:Apache License 2.0
多模态任务:
视觉信息提取(visual-information-extraction):无额外配置
图像字幕生成(image-captioning):无额外配置
标签:
- MLLM-CL
- 领域持续学习(Domain Continual Learning)
- 能力持续学习(Ability Continual Learning)
- MR-LoRA
- 持续学习(Continual Learning)
- 多模态大语言模型(Multimodal Large Language Model, MLLM)
---
<!--- 以上YAML section提供属性/tags描述--->
<!--- 以下为markdown格式的dataset描述--->
## MLLM-CL基准数据集说明
MLLM-CL是一款涵盖领域持续学习与能力持续学习的新型基准数据集。其中前者聚焦于在持续演进的主流领域间开展独立同分布(Independent and Identically Distributed, IID)评估,后者则针对包含新兴模型能力的非独立同分布(Non-IID)场景开展评测。
如需了解更多细节,请参考:**MLLM-CL:面向多模态大语言模型的持续学习** [[论文](https://arxiv.org/abs/2506.05453)]、[[代码](https://github.com/bjzhb666/MLLM-CL/)]。
[赵洪波](https://scholar.google.com/citations?user=Gs22F0UAAAAJ&hl=zh-CN), [朱飞](https://impression2805.github.io/), [郭海洋](https://ghy0501.github.io/guohaiyang0501.github.io/), [王萌](https://moenupa.github.io/), 王润东, [孟高丰](https://scholar.google.com/citations?hl=zh-CN&user=5hti_r0AAAAJ), [张兆翔](https://scholar.google.com/citations?user=qxWfV6cAAAAJ)
针对领域持续学习任务,需使用数据集`RS.tar.gz、Med.tar.gz、AD.tar.gz、Fin.tar.gz、Sci.tar.gz`。
针对能力持续学习任务,需使用数据集`OCR.tar.gz、APP.tar.gz、VP.tar.gz、Math.tar.gz`。
回放数据与路由训练数据可在[MLLM-CL-replaydata](https://modelscope.cn/datasets/MLLM-CL/mllmcl-replaydata)获取。

## 数据格式
所有数据均用于多模态大语言模型(Multimodal Large Language Model, MLLM)的监督微调(Supervised Fine-Tuning, SFT)阶段,JSON文件采用LLaVA监督微调格式。
{
"image": path of image;
"question_id": id;
"conversations": [
{
"from": "human",
"value": "<image>
"+question or question
},
{
"from": "gpt",
"value": answer
}
]
}
## 引用
@article{zhao2025mllm,
title={MLLM-CL: Continual Learning for Multimodal Large Language Models},
author={Zhao, Hongbo and Zhu, Fei and Guo, Haiyang and Wang, Meng and Wang, Rundong and Meng, Gaofeng and Zhang, Zhaoxiang},
journal={arXiv preprint arXiv:2506.05453},
year={2025}
}
## 联系方式
请在我们的GitHub仓库提交Issue。
## 关于我们:MLLM-CL社区

我们是MLLM-CL社区的成员,该社区是一个专注于多模态大语言模型持续学习研究的开源社区。若您对我们的社区感兴趣,欢迎通过GitHub或邮件与我们取得联系。
提供机构:
maas
创建时间:
2025-05-21
搜集汇总
数据集介绍
背景与挑战
背景概述
MLLM-CL是一个用于多模态大语言模型持续学习的基准数据集,涵盖领域和能力两个方面的持续学习。数据集采用LLaVA SFT格式,包含图像、问题和对话内容,适用于模型的监督微调(SFT)阶段。
以上内容由遇见数据集搜集并总结生成


